
КАК СОЗДАТЬ ПРАВИЛЬНЫЙ ROBOTS TXT

Полноценная SEO-оптимизация практически невозможна без настройки «мелочей», которые на проверку оказываются едва ли не важнее ключевых пунктов методички любого сеошника. В этой статье мы научимся создавать со всех сторон правильный robots txt – правила, директивы и структуру.
- Как разрешить индексацию в robots txt
- Создание роботекста
- Как настроить правильный робот txt
- Disallow директива
- Директива Allow
- Директива sitemap в robots txt
- Clean Param
- Директива crawl delay
- Система комментариев
- Проверка роботекста
Вообще, robots (он же роботекст для сайта) – это несложный txt-файл, внутри которого прописываются условия для грамотной индексации поисковиками либо ресурса целиком либо отдельных страничек. Расположен он в корне сайта и к нему поисковик обращается в саму первую очередь, чтобы определить доступность индексирования.
Как разрешить индексацию в robots txt
По умолчанию, содержимое этого файла дает «карт-бланш» для любого рода действий поисковых систем:

В переводе на человеческий этот код разрешает каждому роботу (:*) проиндексировать целый сайт (:/).
По идее, раз такое прописано по умолчанию, тогда зачем вообще что-то менять? Пусть себе индексирует, но нет. Загруженность поисковых роботов достигает космических масштабов, страницы исчисляются миллиардами, а ведь для всех из них нужно подобрать соответствующие пользовательские запросы и просчитать ранжирование, чтобы ответы в самом конечном итоге были релевантны.
Среднего размера сайт может содержать в себе не одну тысячу страниц, которые будут техническими или дубликатами или просто пустышками без полезной информации. А по нашим логичным представлениям поисковый робот должен сканировать именно информативные страницы. Он-то будет, но и лишней «шелухи» при этом просмотрит немало. Это никому не надо. Ресурсы роботов все-таки ограничены. И краулинг-бюджет никто не отменял, львиную долю которого мы рискуем просадить ни на что.
Другими словами, наша задача - открыть для краулеров исключительно полезные страницы.
Создание роботекста
Вариантов сделать правильный robots txt для сайта два. Популярные CMS позволяют плагинами верстать код прямо в админке. Либо «ручками» в любимом текстовом редакторе с последующим перемещением в корень сайта (в папку, где лежит индекс.html). Вы ведь освоили подходящий фтп-клиент к этому моменту? Вобщем, делайте как хотите, главное - не забывайте чекать валидность расположения и корректность кода Я.Вебмастером.
Как настроить правильный робот txt
Верно настроенный файл поможет сайту с поисковой выдачей и оградит от попадания ресурса в категорию «спам» и «частная информация». При этом, прочитать его может любой (для примера зайдите на apple.com/robots.txt), а значит секретную информацию, вроде пароля от хостинга, там точно хранить не стоит :)
Рассмотрим, что должно быть в robots txt в идеале.
- Разберемся в структуре роботекста. Вот примерный вид шаблонного файла рядового сайта:

Видим два блока инструкций, каждый из которых начинается директивой User-agent. Эта директива уточняет – какому конкретно поисковому роботу посвящена инструкция:

Это типовой набор директив, но есть возможность отдельно указать инструкции для других индексаторов, например обработчиков изображений:

Следующая строка за строкой директивы – это команда разрешения (Allow) и запрета (Disallow) индексирования.
Еще один важный момент структуры это файл sitemap в robots txt. Место, где лежит в каталоге xml-карта всего ресурса. Прописывается обычно в самом конце:
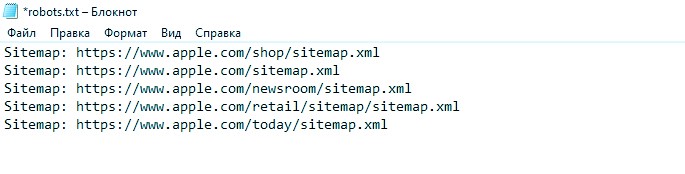
- Разберемся в синтаксисе и общих правилах настройки
Нормы «правописания» в роботексте конечно же есть и они несложные. Просто соблюдайте нижеперечисленное:
- Если файла нет, либо он пуст, или его размер больше 32 килобайт – для индексирования автоматом открывается все содержимое.
- Называться файл должен всегда одинаково – robots.txt. Верхний регистр недопустим, что-то кроме латиницы – тоже.
- Каждая директива, инструкция или команда – это новая строка
- Пробелы не учитываются как символ и ни на что не влияют. Но ведите верстку так, чтобы не заблудиться самим.
- Инструкции не закрываются какими-либо элементами. Начинайте следующую с новой строки и все.
- Система комментариев в наличии. Открываются они знаком #, как в скриншотах выше.
- Каждую директиву снабжайте только одним параметром на строке. Следующая строка – повтор директивы и новый параметр

- Все директивы начинаются с большой буквы. Верно – Sitemap, неверно – SITEMAP
- Символом «слэш» отмечаются страницы и каталоги. К примеру – для китайского робота такие крутые часы почему-то недоступны :)
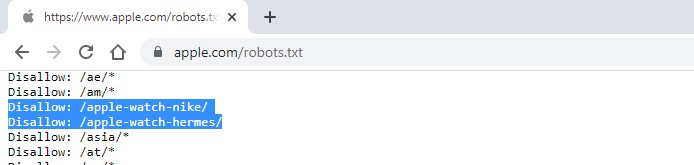
-
Очередность команд не имеет значения, но главной считаться будет Allow, если в юзер-агенте законфликтуют allow disallow
Запрещать краулерам индексировать каждую страницу отдельной директивой излишне. Код следует создавать таким образом, чтобы захватывались все ключевые индексы вашего ресурса. Правильный роботс тхт состоит из небольшого и емкого кода.
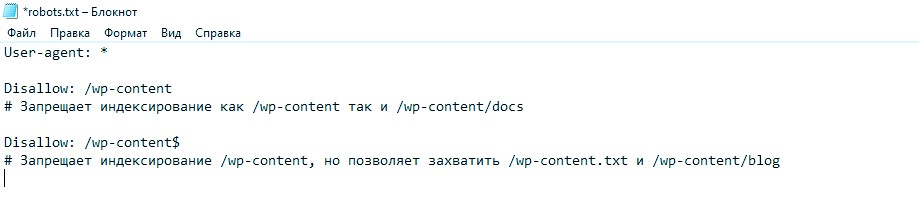
- Спецсимволы. Директивы можно улучшить, если в параметре указать значения * и $. «Звездочка» указывает роботу определенную маску адреса, например:

Символ «доллара», наоборот, уточняет – какую именно папку индексировать запрещено из всего массива одноименных элементов:
Структуру, синтаксис и правила написания кода мы изучили, теперь поехали дальше вникать в главные директивы.
Disallow директива
Это директива запрета индексации страниц:
- с конфиденциальными данными
- которые отображают результаты поиска на сайте
- дублей
- технических данных и логов
- с сервисной информацией

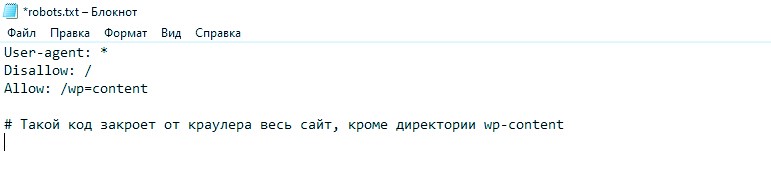
Директива Allow
Этот параметр выдает разрешение на индексирование элементов. Имеет приоритет перед запрещающей директивой:
Директива sitemap в robots txt
Если в первую очередь поисковые боты сканируют пространство на предмет роботекста, то уже в самом файле первым делом ищется расположение xml-карты ресурса. Там изложена вся схематика сайта с путями, линками, датой генерации страничек и прочей не менее важной информацией. Синтаксис элементарный:
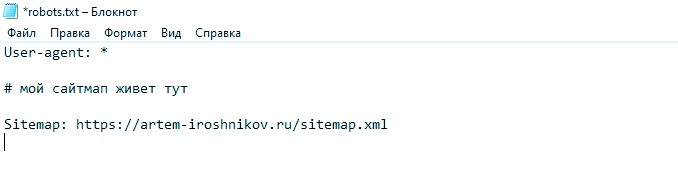
Пренебрегать сайтмапом не следует, это базовый сео-инструмент, своего рода стандарт, необходимый для нормального «участия» в жизни поисковиков. Держите его актуальным и обновляйте регулярно, особенно если ресурс совсем юный.
Clean Param
Этот указатель запрещает роботам изучать страницы, на которых имеются динамические параметры и содержимое их примерно похоже на содержимое главных страничек. К примеру, веб-шопы часто используют Url-адреса для передачи данных пользователей или их идентификаторов. Это капитально лишняя нагрузка, причем бесполезная, значит директива clean-param в robots.txt это ваше решение.
Сейчас поясним наглядно. Допустим, что популярный сайт берет данные гостей на следующих страницах:
https://mapple.com/iphone/buy_iphone.php?Name=vasya&refer=page1&phone_cat=5
https://mapple.com/iphone/buy_iphone.php?Name=petya&refer=page2&phone_cat=5
https://mapple.com/iphone/buy_iphone.php?Name=masha&refer=page3&phone_cat=5
Итак, значение Name это личные данные пользователя, refer – адрес, с которого к mapple.com пришли в гости Vasya и его коллеги. Но итоговый общий результат, что их объединяет – это phone_cat=5 (очень популярная нынче модель :)). Тут и приходит время подключать директиву:

Все эти манипуляции позволят поисковикам понять, что индексировать нужно лишь страницу https://mapple.com/iphone/buy_iphone.php?phone_cat=5
И в случае ее доступности для поисковой выдачи проиндексирована будет именно такая.
Директива crawl delay
Эта фишка указывает роботам через какие промежутки следует заходить к вам в гости. Пригодится, если вас любят сильнее других и от такой краулинговой любви растет лишь нагрузка на серверную вашу часть.
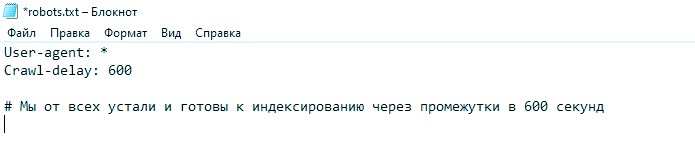
Здесь мы желаем, чтобы краулеры заходили один раз за 10 минут. На самом деле такого не случится, это шутка, потому что например Яндекс допускает максимальное значение директивы лишь в две секунды (а также понимает значения после запятой). Crawl-delay позволяет снизить серверную нагрузку и найти причину сбоев в работе.
Система комментариев
Примеров в скриншотах этой статьи было множество. Начинается коммент после «решетки» и служит для пояснения причины того или иного действия среди оптимизаторов (или чтобы не забыть самому).
Проверка роботекста
После загрузки файла в корень сервера необходимо проверить чтобы он был доступен, корректен и не содержал ошибок.
Напрямую прочитать роботс можно введя адрес ваш-сайт/robots.txt. Если он на месте – значит одной проблемой меньше. Вебмастерки Яндекса и Гугла само собой располагают инструментами для проверки корректности таких файлов и укажут все недочеты, если таковые будут.
В этом руководстве мы по шагам разобрали основы и необходимый минимум для того, чтобы самостоятельно с нуля создать рабочий вариант файла robots.txt и тем самым положить начало для беспроблемной индексации вашего ресурса, экономии краулинг-бюджета и исключить излишнюю серверную нагрузку. Удачи в дальнейшем сео-продвижении вашему сайту!


Запись на курсы
Запись на курс

Комментарии
Добавить комментарий